
지우너
[C# 게임 서버] 멀티쓰레드 프로그래밍(1) 본문
1. Thread 생성
Using System.Threading 을 추가하여 쓰레드를 사용할 수 있도록 만들기.
using System;
using System.Threading;
namespace ServerCore
{
class Program
{
static void MainThread(object state)
{
for (int i = 0; i < 5; i++)
{
Console.WriteLine("Hello Thread!");
}
}
static void Main(string[] args)
{
ThreadPool.QueueUserWorkItem(MainThread);
for (int i = 0; i < 1000; i++)
{
Thread t = new Thread(MainThread);
t.Name = "Test Thread";
t.IsBackground = true;
t.Start();
Console.WriteLine("waitting for Thread");
t.Join();
}
Console.WriteLine("Hello World!");
}
}
}
1.1. Thread 매개 변수 및 함수
Thread 정의, 매개변수, 함수 등의 전체 사용법은 아래 링크를 이용하면 볼 수 있다.
https://learn.microsoft.com/en-us/dotnet/api/system.threading.thread?view=net-6.0
Thread Class (System.Threading)
Creates and controls a thread, sets its priority, and gets its status.
learn.microsoft.com
<쓰레드 생성>
Thread t = new Thread(실행할 함수)
<매개변수>
Thread.Name
말 그래도 쓰레드에 이름을 붙여줌
Thread.IsBackground
C#에서는 쓰레드가 foreground Thread로 만들어진다. Thread.IsBackground를 true로 하면 Main함수가 종료됐을 때, 같이 종료됨. false로 해주고 Thread에
얘가 백그라운드에서 실행이 되도록 함. defalut값은 false
background가 정확히 뭔지 모르겠어서 마이크로소프에서 게시한 문서를 확인해봤다.
Microsoft_Foreground and background threads
Foreground and Background Threads - .NET
Determine or change whether a thread is a background thread or a foreground thread using the Thread.IsBackground property in .NET.
learn.microsoft.com
<함수>
Thread.Start()

운영 체제가 현재 인스턴스의 상태를 실행 중으로 변경하고, 인자로 Object를 전달할 경우 선택적으로 스레드가 실행하는 메서드에서 사용할 데이터가 포함된 객체를 제공
Thread.Join()
강의에서는 쓰레드의 동작이 완료된 후에 그 아래 코드를 실행하게 하는 코드라고 설명되었는데, 설명이 조금 부족한 것 같아 문서를 찾아보았다.

이 인스턴스로 표시되는 스레드가 종료될 때까지 호출 스레드를 차단하는 동시에 표준 COM 및 SendMessage 펌핑을 계속 수행
standard COM과 SendMessage pumping이 뭘까 의문이 생겨 찾아봤다.
( [프로그래밍 원리 007] SendMessage & PostMessage in MultiThreading (1) )
위 코드처럼 쓰레드 1000개를 생성할 수도 있다. 하지만 그렇게 한다고 해서 효율이 1000배가 되는 것이 아니다.
CPU코어는 쓰레드를 왔다갔다하며 동시에 여러 쓰레드가 실행되는 것처럼 보이도록 만든다.(예전 도스 시절에는 1개의 프로그램만 실행시킬 수 있었으나, 해당 방법을 이용하면 여러 프로그램을 실행시켜도 동시에 돌아가는 것처럼 보이게 할 수 있다.→ 프로그램 1에 있는 a쓰레드를 조금 작업한 뒤 프로그램2의 b쓰레드를 조금 작업하고, 프로그램3에 있는 c쓰레드가 작업하도록 매우 빠른 속도로 왔다갔다 하는 것)
그런데 쓰레드의 수가 너무 많아지면 실제로 작업하는 시간보다 여러 쓰레드를 왔다갔다하는 시간이 더 많아질 수 있다
때문에 CPU의 코어수와 쓰레드의 수를 최대한 비슷하게 맞춰주는것이 가장 좋다.
1.2. ThreadPool 개념
ObjectPooling
오브젝트들을 생성&삭제 하지 않고, 자주 쓰는 오브젝트를 풀에다 넣어놓고 꺼내 쓰는 방식 (생성과 삭제가 비용이 큰 연산이기 때문에 자주 쓰는 오브젝트를 반복하여 생성 삭제하면 메모리에 부담이 된다.)
ThreadPool
ObjectPool처럼 쓰레드들이 대기 중인 인력사무소 같은 느낌이다. 단, 쓰레드를 직접 생성하는 방식과 다르게 1000번 반복했을 경우 풀 안에 있는 쓰레드가 작업을 마치고 돌아오면 다음 작업에 재투입하는 형식으로 작동한다. 때문에 너무 긴 작업을 배정할 경우 작업을 마치지 못할 수 있으며, 작업을 수행할 쓰레드가 없어져서 작업을 하지 못하는 상황이 발생할 수 있다.
따라서 ThreadPool을 사용할 때는 되도록 짧을 작업을 넣어주는 게 좋다. 너무 긴 작업을 넣을 시 ThreadPool 전체가 먹통이 될 수 있음
아래와 같이 쓰레드의 최대 갯수를 5개로 설정하고, 5개 쓰레드 모두 무한루프에 빠트리면 그 아래에ThreadPool.QueueUserWorkItem(MainThread);를 해도 "HelloThread!"가 출력되지 못한다.(해당 작업을 할 쓰레드가 작업을 마치지 못하고 계속 갇혀있기 때문)
static void MainThread(object state)
{
for (int i = 0; i < 5; i++)
{
Console.WriteLine("Hello Thread!");
}
}
static void Main(string[] args)
{
ThreadPool.SetMinThreads(1, 1);
ThreadPool.SetMaxThreads(5, 5);
for (int i = 0; i < 5; i++)
{
ThreadPool.QueueUserWorkItem((obj) => { while (true) { } });
}
ThreadPool.QueueUserWorkItem(MainThread);
}
1.3. ThreadPool 관련 함수, 매개변수
https://learn.microsoft.com/en-us/dotnet/api/system.threading.threadpool?view=net-8.0
ThreadPool Class (System.Threading)
Provides a pool of threads that can be used to execute tasks, post work items, process asynchronous I/O, wait on behalf of other threads, and process timers.
learn.microsoft.com
1.4. Task
https://learn.microsoft.com/ko-kr/dotnet/api/system.threading.tasks.task?view=net-8.0
Task 클래스 (System.Threading.Tasks)
비동기 작업을 나타냅니다.
learn.microsoft.com
2. 컴파일러 최적화

우리는 지금까지 Debug모드로 코드를 짜고 있었다. 하지만 나중에 게임을 실제로 배포하고 라이브에 나가게 될 때에는 Release 모드로 바꾸게 된다. Release 모드로 바꾸게 되면 온갖 최적화가 다 들어가서 프로그램이 훨씬 더 빨라진다.
아래의 코드를 Debug모드로 실행시키면 무사히 종료가 되는 반면, Release 모드로 실행시켰을 때는 "종료 대기중"까지만 뜨고 종료되지 않는다(여전히 ThreadMain함수의 while문에 갇혀있다는 의미)
using System;
using System.Threading;
namespace ServerCore
{
class Program
{
// Thread를 사용할 때 각각의 쓰레드는 자신만의 Stack Memory를 할당받아 사용한다.
// _stop과 같은 전역변수는 모든 쓰레드가 공통으로 사용해서 동시에 접근이 가능함.
static bool _stop = false;
static void ThreadMain()
{
Console.WriteLine("쓰레드 시작!");
while (_stop == false)
{
//누군가가 stop 신호를 줄 때까지 기다림
}
Console.WriteLine("쓰레드 종료!");
}
static void Main(string[] args)
{
Task t = new Task(ThreadMain);
t.Start();
// 1초 동안 Sleep하겠다는 의미
Thread.Sleep(1000);
_stop = true;
Console.WriteLine("stop 호출");
Console.WriteLine("종료 대기중");
//Thread 클래스의 join()과 같은 역할
t.Wait();
Console.WriteLine("종료 성공");
}
}
}
"디버그-창-디스어셈블리"를 하면 어셈블리 언어가 나온다.
여기서 보면 Release 모드가 while문 안에 _stop을 true로 바꿔주는 명령이 없어서 아래와 같이 변경하여 최적화했음을 알게된다. 때문에 Main에서 _stop을 true로 바꿔주더라도 반복문을 빠져나갈 수 없게 된 것이다.
if (_stop==false)
{
while(true)
{
}
}
Debug 모드에서는 잘 돌아가는 코드가 Release 모드에서는 오류가 발생할 수 있음을 명심할 것!
3. 캐시이론
캐시란 무엇인가?
CPU, 메모리(RAM) , 하드(SSD)가 있다. 하드는 너무 느리기 때문에 CPU와 소통하지 않는다.
CPU는 RAM과 소통하는데, 우리가 어떤 프로그램을 실행하면 그 데이터는 RAM으로 이동하고, CPU는 그 데이터를 가져온다. 하지만 RAM도 CPU에 비하면 많이 느리다. CPU의 내부나 근처에 캐시메모리를 만들어 그곳에 데이터를 저장하고, CPU는 캐시와 소통한다. 캐시메모리는 램에 비하면 용량이 작다. 그렇기 때문에 중요하다고 판단되는 데이터만 저장해서 사용한다. 캐시메모리는 L1~L3(L은 Level을 의미) 3단계로 나누어 사용한다. L1캐시는 CPU가 가장 먼저 접근하는 메모리로 속도는 가장 빠르지만, 용량은 가장 작다. L3은 용량이 큰 대신 속도는 느리다.
CPU는 우선 L1캐시에 데이터를 요청하고, 여기에 없은면 L2캐시에서 데이터를 읽는다. 여기에도 없으면 L3에 요청하고, 그래도 없으면 RAM에 있는 데이터를 읽게 된다. (유튜브_CPU는 어떻게 작동할까)
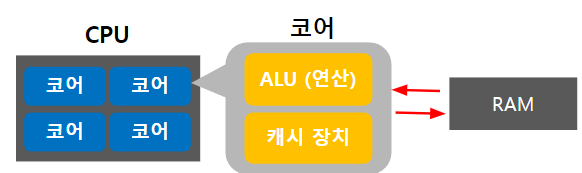
무엇을 캐싱할 것인가?
그렇다면 우리에게 중요한 것은 무엇을 캐시에 저장할지가 중요하다(캐시는 메모리(RAM)보다 훨씬 작기 때문). 캐시는 지역성(Locality)에 기반하여 데이터를 저장한다.
1. Temporal Locality (Locality in Time)
- 시간적으로 봤을 때, 방금 접근한 메모리가 다시 사용될 확률이 높다고 판단
2. Speical Locality (Locality in Space)
- 공간적으로 봤을 때, 접근한 데이터 주변에 있는 데이터를 사용할 확률이 높다고 판단. 대표적인 예시가 배열.
캐시가 잘 작동하고 있는지는 아래 코드를 통해 실험할 수 있다.
static void Main(string[] args)
{
int[,] arr = new int[10000, 10000];
// 5*5 배열이라고 가정하면 아래 순서로 접근
// [1][2][3][4][5] [6][7][8][9][10] [][][][][] [][][][][] [][][][][]
{
long now = DateTime.Now.Ticks;
for (int y = 0; y < 10000; y++)
for (int x = 0; x < 10000; x++)
arr[y, x] = 1;
long end = DateTime.Now.Ticks;
Console.WriteLine($"(y, x)순서 걸린 시간 {end - now}");
}
// 5*5 배열이라고 가정하면 아래 순서로 접근
// [1][6][][][] [2][7][][][] [3][8][][][] [4][9][][][] [5][10][][][]
{
long now = DateTime.Now.Ticks;
for (int y = 0; y < 10000; y++)
for (int x = 0; x < 10000; x++)
arr[x, y] = 1;
long end = DateTime.Now.Ticks;
Console.WriteLine($"(x, y)순서 걸린 시간 {end - now}");
}
}
(y, x)순으로 접근하는 것보다 (x, y)순으로 접근하는 게 시간이 훨씬 덜 걸린다. (y, x)로 접근하면 인접한 메모리를 캐시에 집어넣은 상태이기 때문.

4. Memory Barrier
앞서 Release모드로 컴파일하면 컴파일러가 자동으로 최적화해주어서 예상치 못한 버그가 발생할 수 있음을 보았다.
하드웨어도 비슷하게 최적화를 하고 있다.
4.1. 개념
class Program
{
static int x = 0;
static int y = 0;
static int r1 = 0;
static int r2 = 0;
static void Thread_1()
{
y = 1;
r1 = x;
}
static void Thread_2()
{
x = 1;
r2 = y;
}
static void Main(string[] args)
{
int count = 0;
while (true)
{
count++;
x = y = r1 = r2 = 0;
Task t1 = new Task(Thread_1);
Task t2 = new Task(Thread_2);
t1.Start();
t2.Start();
Task.WaitAll(t1, t2);
if (r1 == 0 && r2 == 0) break;
}
Console.WriteLine($"{count}번 만에 빠져나옴");
}
}
위 코드를 실행하면 while문을 생각보다 쉽게 빠져나오는 것을 볼 수 있다(필자의 경우 대부분 8000번 내외로 빠져나옴). 어떤 경우를 생각해봐도 r1과 r2가 0이 들어갈 수 있는 경우는 없어 보인다.
우리가 입력한 명령어가 서로 의존성이 없는 명령어라고 판단이 되면, CPU는 순서를 자기 마음대로 바꾼다. 자기가 조금 더 빠르게 실행하기 위한 최적의 수를 찾아서 순서를 바꾸는 것.

y에 1을 저장하는 것과 r1에 x를 저장하는 건 서로 연관성이 없는 일이기 때문에 CPU가 마음대로 순서를 바꾼 것이다.
이런 현상을 막기 위한 것이 Memory Barrier다.
Memory Barrier
(A) 코드 재배치를 억제하는 역할
(B) 가시성에 도움
4.2. 코드 재배치를 억제하는 역할
static void Thread_1()
{
y = 1;
Thread.MemoryBarrier();
r1 = x;
}
static void Thread_2()
{
x = 1;
Thread.MemoryBarrier();
r2 = y;
}
위 코드의 Thread_1(), Thread_2() 함수의 바뀌지 않기를 원하는 위치에 Thread.MemoryBarrier()함수를 넣어준다.

다음과 같이 메모리 액세스를 동기화합니다: 현재 스레드를 실행하는 프로세서는 MemoryBarrier() 호출 이전의 메모리 액세스가 MemoryBarrier() 호출 이후의 메모리 액세스 이후에 실행되는 방식으로 명령어의 순서를 변경할 수 없습니다.
(=즉, MemoryBarrier() 호출 이전의 메모리 엑세스가 먼저 실행되고, MemoryBarrier() 호출 이후의 메모리 엑세스가 다음에 실행되도록 한다는 의미)
1) Full Memory Barrier (ASM MFENCE)
여기서 사용된 Thread.MemoryBarrier()는 C#에서의 Full Memory Barrier(어셈블리어로 MFENCE)이다.
위에 적힌 설명처럼 store(y=1, x=1)과 load(r1=x, r2=y)의 순서가 변하지 않도록 고정시킴
2) Store Memory Barrier (ASM SFENCE) / Load Memory Barrier (ASM LFENCE)
조금 더 최적화를 하고 싶다면 반쪽짜리 베리어도 있다. 이름에서 알 수 있듯이 전자는 Store만 막는 메모리 베리어, 후자는 Load만 막는 메모리 베리어이다.
4.3. 가시성에 도움
첫 번째 직원이 자기가 열심히 기록한 것을 실제 전광판에 올렸다 해서 두 번째 직원이 그걸 바로 볼 수 있는 건 아니다.
2번째 직원이 전광판에 있던 데이터를 자기 수첩으로 옮겨야지만(동기화 작업) 똑같은 상황을 볼 수 있게 된다.
아래는 C# 완벽 가이드라는 책에 나온 유명한 예제이다.
int _answer;
bool _done;
void A()
{
_answer = 123;
Thread.MemoryBarrier(); // _answer에 저장한 123을 메모리에 올리기
_done = true;
Thread.MemoryBarrier();// _done에 저장한 123을 메모리에 올리기
}
void B()
{
Thread.MemoryBarrier(); // 메모리에 올라가 있는 _done의 최신 값 동기화
if (_done)
{
Thread.MemoryBarrier(); // 메모리에 올라가 있는 _answer의 최신 값 동기화
Console.WriteLine(_answer);
}
}
A()라는 함수와 B()라는 함수가 2개의 쓰레드에 대해서 동시에 실행이 된다고 가정하고 있다.
그때 베리어를 위와 같이 4번 해주어야 우리가 예상하는 정상적인 상황이 제대로 나온다.
베리어를 두지 않을 경우 앞선 예제처럼 순서가 바뀔 수도 있고, 가시성에도 피해를 입는다.
_answer를 123으로 바꾸고, _done을 true로 바꿔 줬음에도 갱신이 안 되는 문제가 일어날 수도 있다는 의미.
+) volatile도 그렇고, lock이나 아토믹 문법도 내부적으로 베리어로 구현이 되어 있다.
5. Interlocked
아래의 코드를 실행시키면 0이 나와야 할 것 같다(각 쓰레드에서 100000번 더하고 빼주고 있기 때문). 결과는 실행시킬 때마다 조금씩 달라지지만, 전혀 다른 값이 나온다.
가시성의 문제일까? 라는 생각으로 number에 volatile를 붙여줘도 결과는 동일하다(=가시성 문제가 아님).
static int number = 0;
static void Thread_1()
{
for (int i = 0; i < 100000; i++)
{
number++;
}
}
static void Thread_2()
{
for (int i = 0; i < 100000; i++)
{
number--;
}
}
static void Main(string[] args)
{
Task t1 = new Task(Thread_1);
Task t2 = new Task(Thread_2);
t1.Start();
t2.Start();
Task.WaitAll(t1, t2);
Console.WriteLine(number);
}
5.1.Race Condition
둘 이상의 입력 또는 조작의 타이밍이나 순서 등이 결과값에 영향을 줄 수 있는 상태를 말한다. 입력 변화의 타이밍이나 순서가 예상과 다르게 작동하면 정상적인 결과가 나오지 않게 될 위험이 있는데 이를 경쟁 위험이라고 한다.(Wikipedia)
이런 문제가 발생하는 이유를 살펴보려면 number++의 동작 방식을 살펴볼 필요가 있다.
number++을 하는 부분을 Assembly 코드로 보면 아래 사진과 같다(중단점을 찍고 디버그한 후, 디버그-창-디스어셈블리를 클릭하면 코드를 어셈블리 코드로 볼 수 있다). 핵심적인 부분은 드래그하여 블록으로 처리한 부분이다.

어떤 포인터를 가져오는데(dword ptr) [7FFD83BDFB54h]라는 메모리 주소에 있는 걸 ecx 레지스터에 일단 옮겨온다.
Inc라는 걸 이용해 1을 증가시키고 ecx레지스터에 있는 값을 방금 전에 가져왔던 메모리 주소에 다시 넣어주고 있는 것(Assembly는 오른쪽에서 왼쪽으로 넣어줘야 한다)
사실상 number++은 아래의 3줄에 거쳐 실행된다는 의미이다.
int tmp = number;
tmp += 1;
number = tmp;
number++과 number-- 부분을 위의 코드로 치환해보면 왜 문제가 생겼는지 알 수 있다.
static void Thread_1()
{
for (int i = 0; i < 100000; i++)
{
int tmp = number; // 0
tmp += 1; // 1
number = tmp; // number = 1
}
}
static void Thread_2()
{
for (int i = 0; i < 100000; i++)
{
int tmp = number; // 0
tmp -= 1; // -1
number = tmp; // number = -1
}
}Thread_1()의 tmp = 1이 먼저 number에 저장될까, Thread_2()의 tmp = -1이 먼저 실행될까.
이렇게 공유자원을 여러 쓰레드들이 사용하면서 읽고 쓰는 순서에 따라 예상치 못한 결과가 나올 수 있고, 이런 상황을 Race Condition이라고 한다.
5.2. Atomic
위 문제가 일어난 이유는 우리가 numberr++라고 쓴 것이 사실 ①메모리에서 불러와서, ② 1을 증가시킨 후, ③ 다시 그 값을 메모리에 저장 ←이런 3단계로 나누어졌기 때문이다.
Atomic 원자성이라고 번역하는데, 원자는 더이상 (화학반응을 통해) 쪼개질 수 없는 가장 작은 단위를 이르는 용어이다. 이름처럼 Atomic은 어떠한 작업이 실행될 때 언제나 완전하게 진행되어 종료되거나, 그럴 수 없는 경우 실행을 하지 않는 경우를 말한다. 원자성을 가지는 작업은 실행되어 진행되다가 종료하지 않고 중간에서 멈추는 경우는 있을 수 없다.
기계어 수준의 실행 명령어들은 각각 원자성을 가지고 있다. 예를 들어, ADD와 LOAD의 명령어 자체는 각각 원자적이므로 ADD, LOAD의 각각의 명령어 단위는 실행하는 도중에는 인터럽트 등에 의해 중단될 수 없다. 반면, ADD와 LOAD각각의 명령어 자체만이 원자적이므로 ADD 명령어를 끝낸 후와 LOAD명령어를 실행하기 전 그 사이에는 인터럽트가 걸릴 수 있다.(wikipedia)
원자성에 대한 이야기는 멀티스레드 뿐만 아니라 데이터베이스에서도 다루는 내용이다.
(게임) 상점에서 100골드 짜리 아이템을 구매한다고 가정해보자. 우리는 플레이어의 골드에서 100을 빼준 다음 인벤토리에 해당 아이템을 넣어주게 된다.
그런데 이 작업을 원자적으로 처리하지 않으면 어떤 일이 발생할까? 플레이어의 골드를 100 뺀 순간 불행하게 서버가 크래쉬 나서 서버가 다운된다고 생각해보자. 100골드는 줄어서 DB에 저장되는데 아이템은 인벤토리에 추가되지 않는 상태가 발생할 것이다.
그래서 어떤 동작이 한 번에 일어나야 한다는 것이 굉장히 중요한 개념이 되는 것이다.
5.3.Interlocked
원자성을 보장해주기 위해 사용하는 것이 Interlocked이다.
Interlocked Class (System.Threading)
Interlocked Class (System.Threading)
Provides atomic operations for variables that are shared by multiple threads.
learn.microsoft.com
위의 코드에 interlocked를 적용하는 방법은 간단하다.
static void Thread_1()
{
for (int i = 0; i < 100000; i++)
{
Interlocked.Increment(ref number);
}
}
static void Thread_2()
{
for (int i = 0; i < 100000; i++)
{
Interlocked.Decrement(ref number);
}
}


함수에 대한 설명은 위와 같이 나온다. 원자 연산(CPU 명령에서 연산을 원자적으로 만들어주는 명령이 있다)으로 지정된 변수를 증가/감소시키고, 그 결과를 저장한다.
→ 당연히 성능에서의 손실(Thread_1()의 interlocked가 먼저 실행된다고 치면 해당 작업이 최종적으로 끝날 때까지 Thread_2()의 interlocked가 기다려야 하기 때문)이 있기 때문에 남발하는 것은 좋지 않음
Interlocked 계열의 함수를 사용할 때는 애초에 내부적으로 앞서 배운 MemoryBarrier를 간접적으로 사용하고 있기 때문에, 가시성 문제는 발생하지 않는다.
+) Interlocked.Increment(ref number)에서 인자로 ref를 넘겨주는 이유
ref keyword - C# Reference - C#
ref keyword - C# Reference
learn.microsoft.com
Increment/Decrement 함수에 레퍼런스로 인자를 넣어주고 있다. 즉, 참조값으로 넣어주고 있다고 생각을 하면 된다. 다시 말해 number라는 수치 자체를 함수의 인자로 넣는 것이 아니라 number의 주소값을 넣어주고 있는것.
ref 키워드가 없을 경우 여기서는 int자체를 넣어주게 되니까 int의 값을 복사해서 이 Increment/Decrement에 넣어준다는 이야기가 된다. 근데 이렇게 하면 말이 안 되는 게 number의 값을 메모리에서 가져오는 순간 이미 다른 Thread가 접근해서 수정할 수도 있다(Race Condition문제가 해결되지 않는다는 문제점).
ref를 붙여서 레퍼런스를 인자로 넣어줬다는 것은 number가 어떤 값인지 알지는 못하지만, 여기에 있는 값을 참조해서(즉, 이 주소에 가서) 안에 있는 숫자를 무조건 1 증가/감소 시키라는 명령을 내린 것.
ref가 붙은 것과 아닌 것의 차이를 잘 알아야 함.
static void Thread_1()
{
for (int i = 0; i < 100000; i++)
{
int prev = number;
Interlocked.Increment(ref number);
int next = number;
}
}
싱글스레드라고 생각하면 prev와 next가 1차이가 날 것 같다. 하지만 아니라는 것!!! 이런 싱글스레드 마인드를 버려야 한다. number라는 변수는 모든 스레드가 공유하는 변수인데, 그걸 이런 식으로 꺼내와서 사용는 건 말도 안 된다.
왜냐하면 우리가 꺼내와서 쓰느 순간에도 누군가 해당 변수를 건드려서 값이 바뀔 수도 있기 때문이다.
증가된 값을 추출하고 싶을 때는 따라서 함수의 return값을 이용하여 아래와 같이 작성해주어야 한다.
static void Thread_1()
{
for (int i = 0; i < 100000; i++)
{
int val = Interlocked.Increment(ref number);
}
}
[참고 사이트]
[C#과 유니티로 만드는 MMORPG 게임 개발 시리즈] Part4: 게임 서버
C#과 유니티로 만드는 MMORPG 게임 개발 시리즈 강의 노트
컴퓨터 구조 Cache (Locality, Temporal Locality, Spatial Locality, Direct-Mapped-Cache, 캐시 동작, 캐시)
[프로그래밍 원리 007] SendMessage & PostMessage in MultiThreading (1)
'Programming > Server' 카테고리의 다른 글
| [C# 게임서버] 네트워크 프로그래밍(2) (0) | 2024.01.19 |
|---|---|
| [C# 게임서버] 네트워크 프로그래밍(1) (0) | 2024.01.16 |
| [C# 게임 서버] 멀티쓰레드 프로그래밍(4) (0) | 2024.01.14 |
| [C# 게임 서버] 멀티쓰레드 프로그래밍(3) (0) | 2024.01.12 |
| [C# 게임 서버] 멀티쓰레드 프로그래밍(2) (0) | 2024.01.11 |



